In diesem Blogartikel mixen wir einen Cocktail aus Google BigQuery, Google Analytics 4 (GA4) und Looker, um Insights zu gewinnen. Die Mischung richtet sich an Marketing-Analysten und Data Engineers in Branchen von IT über Retail bis Banking – egal ob im agilen Startup oder im Grosskonzern. Dabei gilt stets: lieber Klartext als abgehobenes Buzzword-Bingo. In den nächsten Abschnitten zeige ich dir praxisnahe Use Cases und typische Architekturmodelle für Realtime Analytics mit BigQuery, GA4 & Looker – von der Datenpipeline über Live-Dashboards bis zur Entscheidungsautomatisierung.
Warum Realtime Marketing Analytics?
Heutzutage spielt Schnelligkeit eine entscheidende Rolle: Wer Marketing-Daten live im Blick hat, kann Chancen nutzen, Probleme sofort erkennen und schneller reagieren als die Konkurrenz. Viele Unternehmen merken jedoch, dass es gar nicht so einfach ist, an Echtzeit-Daten zu kommen – speziell in Google Analytics 4. Die GA4-Oberfläche bietet nur begrenzte Live-Einblicke (maximal ca. die letzten 30 Minuten), und es ist „beinahe unmöglich“, aktuelle oder sogar gestrige Daten direkt dort abzurufen. Hier kommt die Kombination aus BigQuery und Looker ins Spiel: Sie ermöglicht es, ein eigenes Echtzeit-Dashboard aufzubauen, das z. B. die Daten von heute aus Conversion-Reports oder Demografie-Übersichten zeigt. Kurz gesagt: Realtime Marketing Analytics bedeutet, dass du deine Kampagnen und Kundeninteraktionen beobachten kannst, während sie geschehen – und das eröffnet völlig neue Möglichkeiten. (Natürlich benötigt nicht jedes Unternehmen jedes Detail in Echtzeit, aber für viele dynamische Marketing-Situationen ist es ein echter Game-Changer.)
Use Cases für Realtime Analytics im Marketing
Was lässt sich nun konkret mit Echtzeit-Daten anstellen? Hier einige praxisnahe Use Cases, bei denen Realtime Analytics den Unterschied macht:
-
Echtzeit Kampagnen-Optimierung: Du siehst minutengenau, wie deine Kampagne performt und kannst im laufenden Flug Anpassungen vornehmen. Beispielsweise lässt sich ein unerwarteter Traffic-Peak in BigQuery sofort erkennen und spontan das Budget umverteilen oder die Aussteuerung anpassen. So werden Marketingentscheidungen agil wie nie zuvor.
-
Personalisierung & Segmentierung in Echtzeit: BigQuery erlaubt es, Zielgruppen ad-hoc anhand beliebiger Ereignisse zu segmentieren – von Nutzern, die etwas in den Warenkorb legen aber nicht kaufen, bis zu treuen Viel-Bestellern – und diese Segmente direkt zurück in Google Analytics oder Werbeplattformen zu spielen. Das Ergebnis: personalisierte Ansprache nahezu in Echtzeit, z. B. durch individuelle Angebote für gerade aktive High-Value Customers.
-
Live-Monitoring & Alerts: Nach einem Website-Relaunch oder einer neuen Kampagne ist ein Live-Dashboard Gold wert, um Daten sofort beim Eintreffen zu überwachen. So können Probleme proaktiv erkannt und behoben oder Chancen unmittelbar genutzt werden z. B. wenn plötzlich das Conversion-Tracking ausfällt oder eine KPI verdächtig schwankt, weisst du es nicht erst am nächsten Tag, sondern innerhalb von Minuten und kannst direkt eingreifen.
-
A/B-Tests und Produkt-Launches beobachten: Ähnlich wichtig sind Echtzeit-Analytics, um Experimente oder Neueinführungen zu begleiten. Läuft ein A/B-Test gerade aus dem Ruder (z. B. Variante B konvertiert deutlich schlechter), kann ein Echtzeitblick in die Daten helfen, frühzeitig abzubrechen oder gegenzusteuern. Bei schrittweisen Produkt-Launches (z. B. Feature-Rollouts auf Teilgruppen) lassen sich via Live-Dashboard unmittelbare Auswirkungen verfolgen, ohne auf den nächsten Tag warten zu müssen.
- Automatisierte Entscheidungen & Aktionen: Realtime Analytics dient nicht nur dem Menschen – es kann auch direkt Maschinen anstossen. Mit prädiktiven Modellen in BigQuery ML lassen sich z. B. Zielgruppen mit hoher Kaufwahrscheinlichkeit oder abwanderungsgefährdete Kunden identifizieren. Solche Insights können automatisch in Kampagnen einfliessen: Etwa könnte eine Decision Engine automatisch einen Gutschein per E-Mail schicken, wenn ein Kunde ein hohes Churn-Risiko aufweist, oder Gebote in Werbenetzwerken dynamisch anpassen, sobald bestimmte Echtzeit-Signale auftreten.
Architektur und Datenpipeline: BigQuery, GA4 & Looker in Aktion
Eine robuste Datenpipeline ist das technische Rückgrat der Echtzeit-Analyse. Wie sieht so ein Setup unter der Haube aus? Im Kern fliessen die Analytics-Events (etwa von GA4 streaming) in ein zentrales Warehouse (BigQuery). Dort können sie transformiert, mit anderen Daten kombiniert und für verschiedene Zwecke aufbereitet werden. Darauf aufbauend greifen dann Live-Dashboards und automatisierte Entscheidungstools. Unten zeige ich eine typische Architektur mit Google-Cloud-Komponenten für Realtime Analytics.
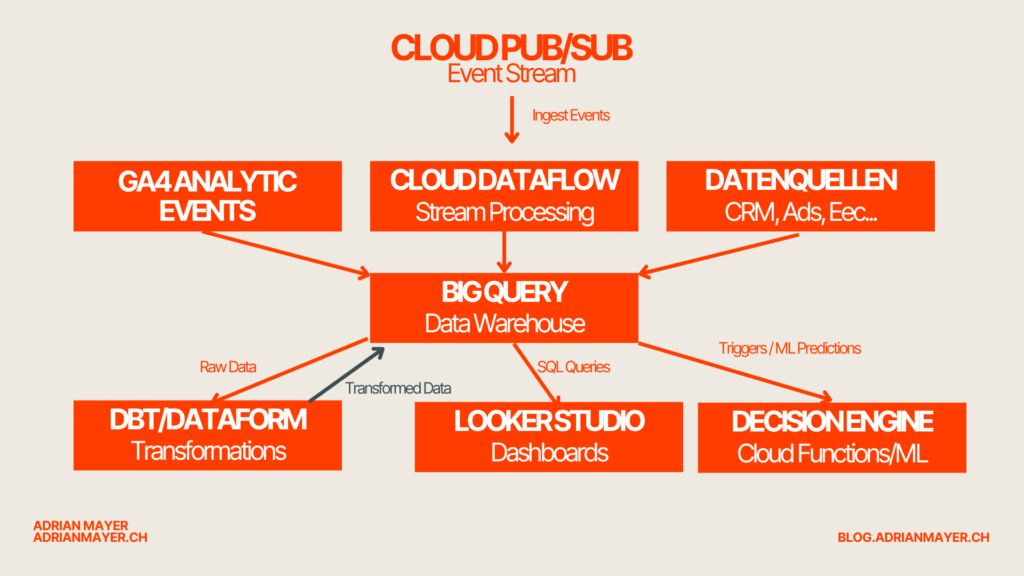
Daten-Ingestion & Streaming
Die Datenerfassung beginnt typischerweise mit Ereignisdaten aus deinen digitalen Kanälen. Google Analytics 4 spielt dabei eine Schlüsselrolle: GA4 bietet eine native Verknüpfung zu BigQuery, und mit der Streaming-Export-Option lassen sich die gesammelten Events nahezu in Echtzeit (innerhalb von Minuten) in BigQuery verfügbar machen. Für jeden Tag wird ein sog. events_intraday_YYYYMMDD-Table angelegt, der kontinuierlich mit den aktuellen Events befüllt wird. So musst du nicht mehr warten, bis der tägliche Export alle Daten am nächsten Morgen liefert – ein lästiger Zeitverzug von bis zu 72 Stunden entfällt. Stattdessen kannst du bereits im Laufe des Tages auf die frischen Events zugreifen, auch bevor GA4 sie final verarbeitet hat. (Hinweis: Die intraday-Daten sind u. U. nicht 100 % vollständig oder bereinigt, da spät eintreffende Hits oder Korrekturen erst im Tagesexport berücksichtigt werden. Für Monitoring und zeitnahe Analysen sind sie dennoch äusserst wertvoll.)
Neben GA4-Events können natürlich auch andere Datenquellen in die Pipeline einfliessen. Hier kommen Streaming-Plattformen wie Google Pub/Sub ins Spiel. Pub/Sub fungiert als skalierbarer Echtzeit-Message-Broker, um Events aus verschiedenen Quellen aufzunehmen – seien es Klicks aus einer App, IoT-Sensordaten oder Events von deiner Website, falls du eine eigene Tracking-Lösung ergänzt. Ein typisches Setup in der Google Cloud nutzt dann Cloud Dataflow (auf Basis von Apache Beam), um die Pub/Sub-Events in Echtzeit zu verarbeiten und ins Warehouse zu schreiben. BigQuery übernimmt schliesslich als zentrales Data Warehouse die dauerhafte Speicherung aller eingehenden Datenströme. Für weniger zeitkritische Daten (z. B. CRM-Daten oder Bestandsinformationen) kann auch ein Batch-Loading in BigQuery sinnvoll sein – entweder durch regelmässige Exporte oder über Tools/APIs. Die gute Nachricht: BigQuery ist ausgelegt auf die Analyse massiver Datenmengen in Echtzeit. Die Infrastruktur skaliert automatisch mit dem Datenaufkommen, und dank Standard-SQL-Support kannst du dich voll auf Abfragen und Insights konzentrieren, statt auf Datenbankadministration.
Transformation & Orchestrierung
Rohdaten sind selten direkt für Dashboards oder Machine Learning geeignet. Deshalb folgt in der Pipeline der Schritt der Daten-Transformation und -Modellierung. Hier werden die GA4-Events und andere Rohdaten in ein Format gebracht, das Analysen und Reporting vereinfacht – zum Beispiel durch Aggregations (Sessions, Conversions pro Stunde), Aufbereitung von User-Journey-Daten oder Anreicherung mit Stammdaten.
Ein Ansatz, der sich bewährt hat, ist ELT (Extract-Load-Transform): Zuerst alle Daten in BigQuery laden (durch den Streaming-Import haben wir das bereits erledigt) und dann direkt in BigQuery transformieren. Tools wie dbt (data build tool) oder Dataform unterstützen dabei, komplexe SQL-Transformationen in gut strukturierte Workflows zu verpacken. Dataform (mittlerweile in BigQuery als Cloud Dataprep integriert) ermöglicht es, bewährte Software-Engineering-Praktiken auf Datenpipelines anzuwenden, um skalierbare und robuste Transformationen sicherzustellen. Beispielsweise kann man ein Dataform-Repository aufbauen, das autonom sämtliche notwendigen Reporting-Tabellen erstellt – Schritt für Schritt, in der richtigen Reihenfolge von Staging-Tabellen bis zu Dimensionen und Fakten. Änderungen am Datenmodell werden versioniert, getestet (Stichwort assertions für Datenqualität) und automatisch ausgeführt. Ähnliches gilt für dbt, das ebenfalls auf Modellierung via SQL und Orchestrierung von Abhängigkeiten setzt, allerdings in der Regel via externer Scheduler ausgeführt wird.
Für die Orchestrierung komplexerer Workflows bietet sich Cloud Composer (Google Cloud’s Managed-Airflow) an. Composer dient als übergeordneter Fahrplan, um verschiedene Jobs zu steuern – etwa um tägliche Batch-Ladevorgänge mit kontinuierlichen Streaming-Updates zu verzahnen oder um berechnete Machine-Learning-Pipelines anzustossen. So kannst du sicherstellen, dass z. B. zunächst die neuesten GA4-Daten eingespielt, dann die Transformations-SQL-Jobs (via dbt/Dataform) ausgeführt und anschliessend die Ergebnisse an das Dashboard geliefert werden.
Als Beispiel, wie eine Transformation in BigQuery aussehen kann, betrachten wir eine einfache SQL-Query, die GA4-Eventdaten aus den letzten Tagen kombiniert. Angenommen, wir möchten heutige Live-Daten (Intraday-Events) und die der vorigen 7 Tage zusammenführen, um die Top-Event-Typen der letzten Woche inklusive heute zu ermitteln. Dies lässt sich mit einem sogenannten Wildcard-Tabellen-Query elegant lösen:
-- Kombiniere GA4 Event-Daten der letzten 7 Tage + heute (Intraday)
WITH events AS (
SELECT user_pseudo_id, event_name
FROM `projekt.analytics.events_intraday_*`
WHERE _TABLE_SUFFIX = FORMAT_DATE('%Y%m%d', CURRENT_DATE()) -- heute (Intraday-Tabelle)
UNION ALL
SELECT user_pseudo_id, event_name
FROM `projekt.analytics.events_*`
WHERE _TABLE_SUFFIX BETWEEN
FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY))
AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) -- letzte 7 Tage (Daily-Tables)
)
SELECT event_name, COUNT(DISTINCT user_pseudo_id) AS unique_users
FROM events
GROUP BY event_name
ORDER BY unique_users DESC;
In obiger Query werden alle Events der letzten Woche plus die aktuellen vom heutigen Tag zusammengeführt (UNION ALL). Anschliessend wird ausgezählt, wie viele eindeutige Nutzer (unique users) jedes Event (Event-Name) hatten. Solche Abfragen liessen sich per Scheduled Query regelmässig in BigQuery ausführen oder via dbt als Materialisierung (z. B. als View oder Table) ablegen. Die Ergebnisse bilden dann die Grundlage für Berichte und Dashboards.
Nächste Woche werfen wir den Scheinwerfer auf die Kür:
Wie du diese Insights nicht nur visualisierst, sondern in messerscharfe Entscheidungen verwandelst – automatisiert und in Echtzeit. Von Looker Actions über MS Teams-Alerts bis hin zu intelligenten Triggern mit Cloud Functions und BigQuery ML.
Stay tuned – nächste Woche wird’s operativ.
Und ja: Es wird verdammt effektiv.